
Google у липні 2024 року стала єдиною пошуковою системою, яка може показувати результати з Reddit. Для DuckDuckGo, Bing, Mojeek та інших пошуковиків контент від Reddit заблоковано.
Чи відображають контент від Reddit пошуковики?
Як пише видання 404 Media, користувачі Bing, DuckDuckGo, Mojeek, Qwant й інші пошукові системи, крім Google, шукаючи результати з Reddit за запитом «site:reddit.com», не побачать жодного результату за останній тиждень. DuckDuckGo станом на липень показує сім покликань під час пошуку на Reddit, але не надає жодних даних про те, куди ці покликання ведуть, натомість з’являється повідомлення: «Ми хотіли б показати вам опис, але сайт не дозволяє нам це зробити».
Старі результати все ще відображатимуться, але ці пошукові системи більше не можуть «сканувати» Reddit, а це означає, що Google — єдина пошукова система, яка надалі показуватиме результати з сайту. Пошук у Reddit все ще працює на Kagi, незалежній платній пошуковій системі, яка купує частину свого пошукового індексу у Google.
Microsoft підтверджує, що Reddit у липні оновив файл robots.txt, заборонивши Bing та деяким іншим пошуковим системам сканувати його сайт.
«Сканери Bing справді заблоковано, тому що Reddit використовував виявлення IP, щоб показати пошуковим системам одну версію свого файлу robots.txt, а людям — іншу версію файлу robots.txt», — йдеться в публікації Search Engine Land.
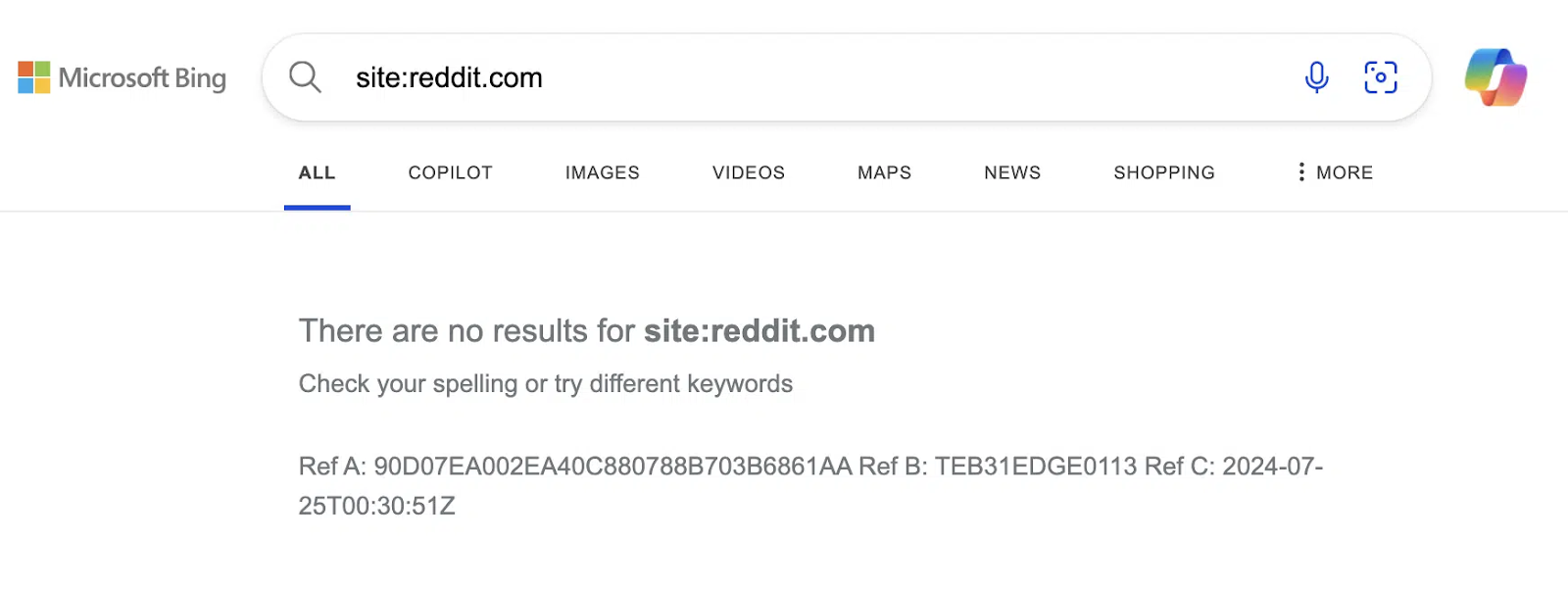
Як Reddit блокує доступ пошуковиків?
Robots.txt — це текстовий файл, що надає чи блокує ботам доступ до вебсайту. Сайти з файлом robots.txt можуть зробити виняток і надати доступ боту Google — Googlebot.
Reddit протидіє використанню свого контенту компаніями для навчання моделей штучного інтелекту, тому вжив публічних і агресивних заходів. 2023 року Reddit почав стягувати плату за доступ до свого API, що зробило багато зі сторонніх застосунків дорогими для використання.
На додаток до кількох покликань на нову «політику публічного контенту» Reddit, файл Robots.txt містить інструкцію, що жоден бот не може сканувати жодну частину сайту.
«Reddit вірить у відкритий інтернет, але не у зловживання публічним контентом», — ідеться в оновленому файлі robots.txt.
У червні цього року Reddit заявив, що спостерігає зростання кількості комерційних організацій, які сканують його контент, порушуючи умови співпраці й політику.
«У найближчі кілька тижнів ми оновимо наші інструкції robots.txt, щоб вони були максимально чіткими: якщо ви використовуєте автоматизованого бота для доступу до Reddit, ви мусите дотримуватися наших умов і політик, і вам потрібно поговорити з нами», — заявити в компанії.
Які переваги отримує Google?
Монополія Google на пошук зараз активно перешкоджає іншим компаніям конкурувати з нею. І хоча ні Reddit, ні Google не відповіли на запит про коментарі, схоже, що виключення інших пошукових систем є результатом багатомільйонної угоди. 2024 року Reddit оголосив, що підписав угоду з Google на $60 млн, щоб ліцензувати контент платформи для навчання моделей штучного інтелекту.
Водночас прессекретар Reddit Тім Ратшмідт у коментарі The Verge сказав, що їхнє рішення не пов’язане з недавнім партнерством з Google.
«Ми вели дискусії з кількома пошуковими системами. Ми не змогли досягти домовленостей з усіма з них, оскільки деякі з них не можуть або не хочуть давати обов’язкові обіцянки щодо використання контенту Reddit, включно з використанням для ШІ», — каже Ратшмідт.
Які подальші дії Reddit?
CEO Reddit Стів Хаффман закликав Microsoft, Anthropic, Perplexity та інші компанії укладати з компанією угоди щодо оплати за використання контенту для скрапінгу.
«Без цих угод ми не маємо права голосу і не знаємо, як відображаються наші дані й для чого вони використовуються, що ставить нас у ситуацію, коли ми змушені блокувати тих, хто не бажає погодитися з нашими умовами співпраці», — сказав Хаффман.
Він заявив, що Microsoft використовувала дані Reddit для навчання свого штучного інтелекту й узагальнення контенту в результатах пошукової системи Bing, не повідомляючи про це компанію. Дані Reddit також продали через API Bing іншим пошуковим системам.
CEO Reddit покликається на нещодавній коментар CEO Microsoft AI Мустафи Сулеймана про те, що публічні дані в інтернеті — це «безплатне програмне забезпечення».
«Microsoft, Anthropic і Perplexity поводяться так, ніби весь контент в інтернеті безплатний для них», — каже Хаффман.
У відповідь на зникнення результатів пошуку Reddit із Bing, керівник відділу пошуку Microsoft Хорді Рібас заявив на X: «Reddit заблокував пошук Bing на їхньому сайті, надаючи перевагу іншій пошуковій системі та впливаючи на конкуренцію з Bing і пошуковими системами, що працюють на базі Bing».
«Я думаю, що традиційний обмін цінностями з пошуковими системами змінився. Пошук, узагальнення та навчання зливаються, і обмін сканування [системами ШІ] на зворотний трафік стає брудним», — сказав Хаффман
Представниця Anthropic Дженніфер Мартінес заявила, що Reddit був у списку заблокованих сайтів для їхніх вебсканерів із середини травня й відтоді компанія не додавала жодних URL-адрес із Reddit до свого сканера: «Ми поважаємо robots.txt, прийнятий галуззю сигнал для блокування вебсканування».
Microsoft відмовилася коментувати цю історію. Perplexity не відповів на запит про коментар.
Нагадаємо, що OpenAI у травні 2024 року підписала угоду про доступ до контенту Reddit. Соцмережа отримує доступ до технологій компанії зі створення штучного інтелекту, а OpenAI зможе в режимі реального часу додавати публікації з Reddit до відповідей ChatGPT. Також News Corp, The Atlantic і Vox Media, The Financial Times уклали ліцензійні угоди з OpenAI. На чому розробники навчають свої моделі штучного інтелекту читайте тут.





