
У травні 2024 року ШІ-компанія Perplexity запустила Pages — інструмент на основі штучного інтелекту для генерування вебсторінок на основі пошукових запитів. Pages надає змогу візуально доповнювати статті, робити докладні звіти, структурувати й розбивати їх на підрозділи. Які функції має Pages, чи бачить їх Google та що показало тестування медійниками — зібрали в цьому матеріалі.
Які функції має Pages від Perplexity?
Як пишуть розробники, Pages спрощує процес роботи над контентом.
Сторінки можна легко створювати, упорядковувати та ділитися інформацією. Користувачі можуть отримати структуровану й відформатовану статтю на будь-яку тему. Публікувати вебсторінки можна в бібліотеці Perplexity та ділитися ними зі своєю авдиторією.
Є змога налаштувати тон публікації відповідно під запит авдиторії — для пересічних читачів або експертів у відповідній темі тощо.Швидка адаптація — користувачі можуть змінювати структуру статті — додавати, переставляти або видаляти розділи.
Додавання візуального матеріалу, згенерованого Pages, завантаженого з галереї користувачів або з інтернету.
Для кого створений інструмент?
- Викладачі з допомогою Perplexity Pages можуть розробити навчальні посібники для учнів, розбивати складні теми на легко засвоювані.
- Дослідники створюватимуть докладні звіти про результати своєї роботи для ширшої авдиторії.
- Усі охочі можуть створити посібники за своїми інтересами.
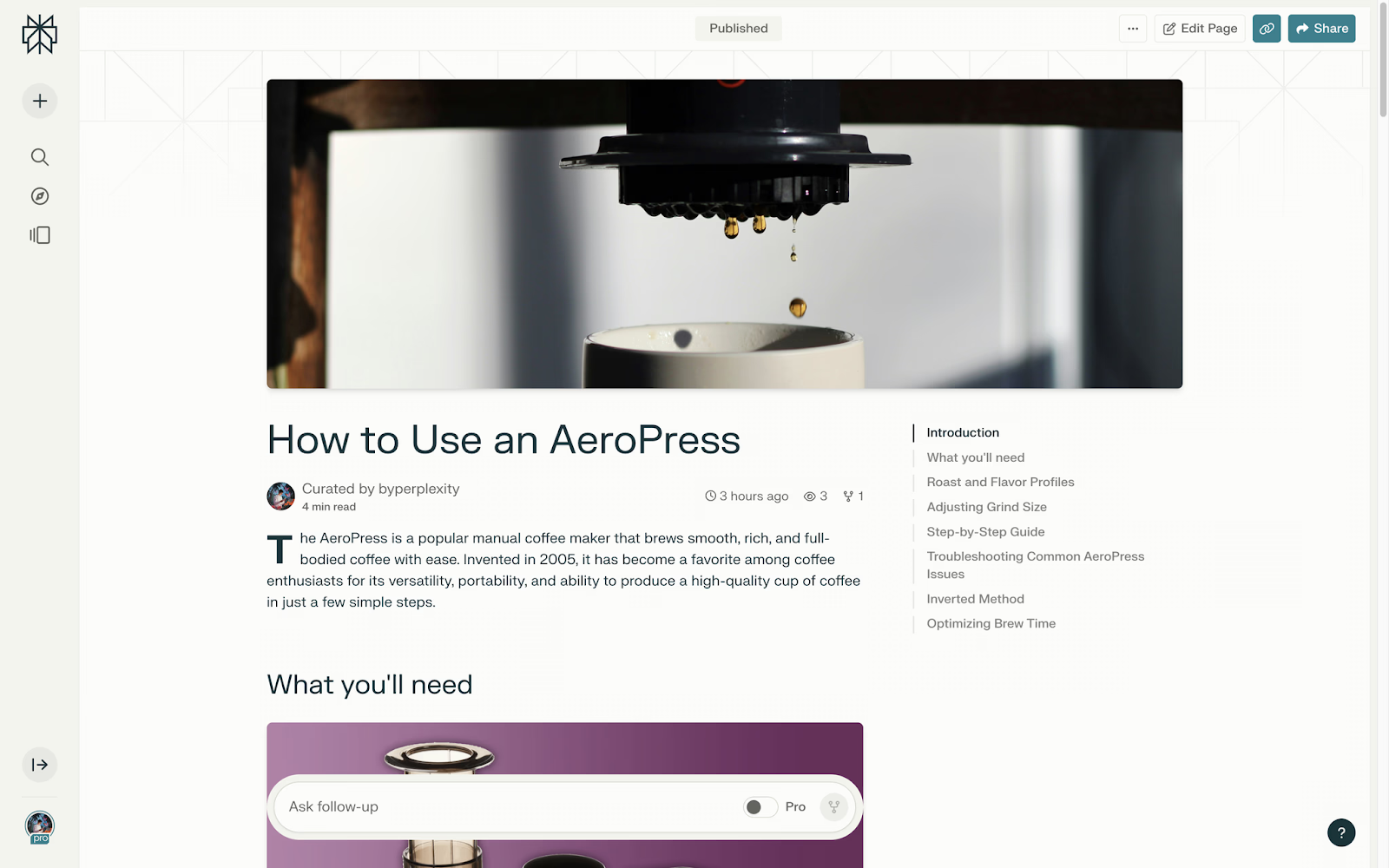
Написання посібника Kubernetes CronJobs

Як працює сервіс?
Користувачі вводять у поле промпт, про що йдеться в їхньому матеріалі, або те, що вони хочуть знати. Perplexity шукає інформацію, а потім починає писати статтю, розбиваючи інформацію на розділи, покликаючись на деякі джерела, а потім додаючи візуальні елементи.
Користувачі можуть зробити цей матеріал деталізованим або лаконічним, а також змінити зображення, які використовує Perplexity. Однак не можна редагувати створений ним текст.
Повний путівник тенісними кортам Сан-Франциско
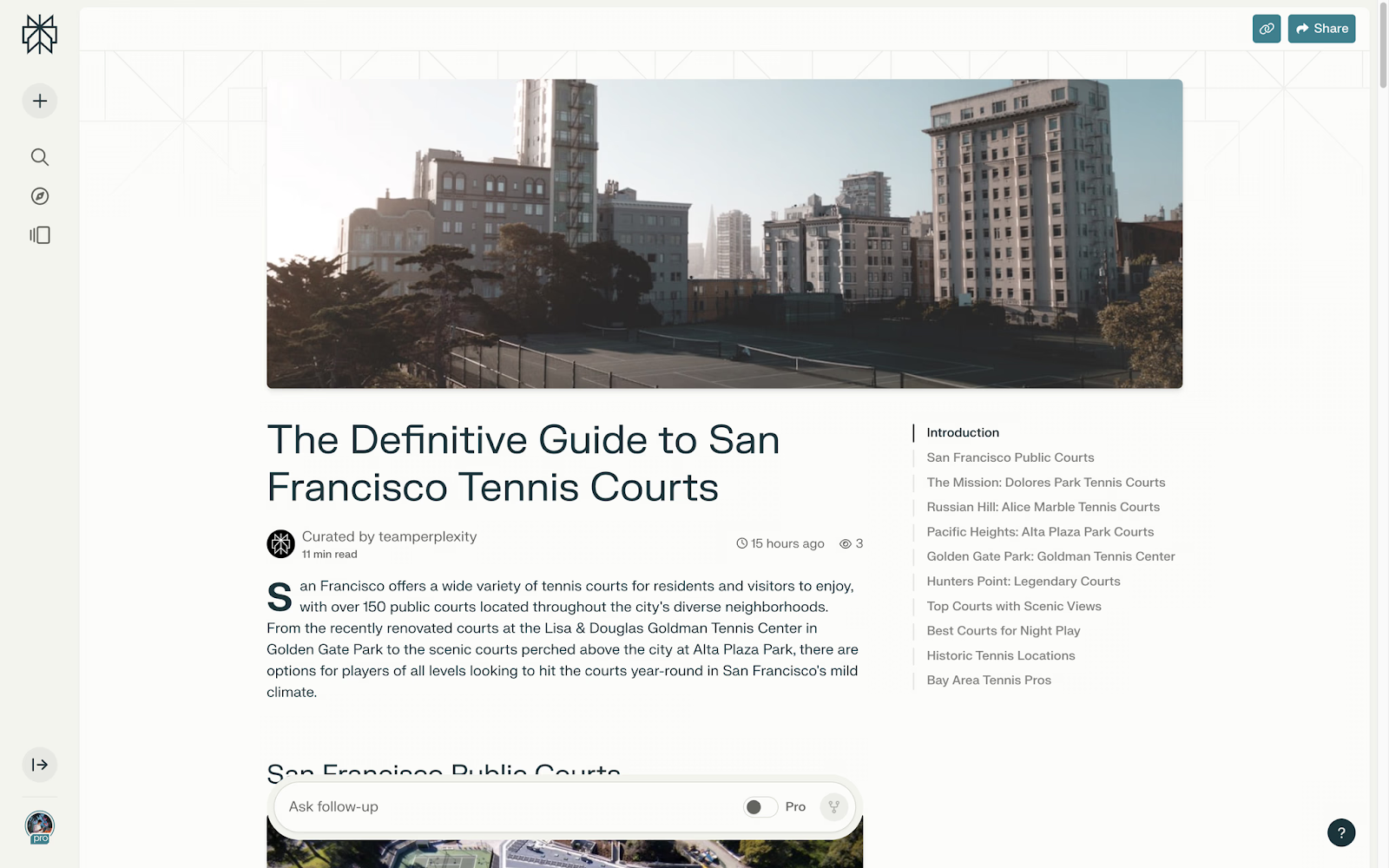
Як медійники тестували інструмент
Журналістка The Verge Емілія Девіс скористалася Pages, щоб побачити, як це працює. За її словами, сервіс не орієнтований на людей, які вже мають можливість поділитися своїми знаннями.
«Я хотіла побачити, як він може розбивати складні теми та чи може це допомогти у важкому завданні — представленні щільної інформації різним авдиторіям. Серед інших тем я попросив Perplexity Pages створити сторінку про “конвергенцію квантових обчислень і штучного інтелекту та їхній вплив на суспільство” для трьох типів авдиторії. Основна відмінність між авдиторіями, здається, полягає в жаргоні в письмовому тексті та типі вебсайту, з якого він бере дані. Кожен створений звіт береться з різних джерел, зокрема зі вступних публікацій у блозі, подібних до цієї від IBM. Він також покликався на Вікіпедію», — ідеться у відгуку журналістки The Verge.
Девіс зазначає, що Perplexity зробив непогану роботу, пояснивши основи квантових обчислень і те, як ШІ вписується в цю технологію. Але «дослідження» не було настільки глибоким, наскільки могла би зробити людина. У більш просунутій версії навіть не йшлося про «конвергенцію квантових обчислень і ШІ». Pages знайшла пости в блогах, де йшлося про переламні моменти у квантових технологіях, коли квантові технології стали комерційно доступними.
Потім Девіс попросила Pages написати про нього самого звіт, сервіс взяв інформацію лише з її персонального сайту та статті на сайті її школи, а не з інших публічних джерел, зокрема зі сторінки автора на The Verge. Крім того, в ній іноді докладно розповідалося про речі, які не мали жодного стосунку до медійниці.
Девіс підсумовує, що Pages робить поверхневий пошук і пише за вас, але це не є дослідженням. Perplexity стверджує, що Pages допоможе викладачам розробляти «всеосяжні» навчальні посібники для студентів, а дослідникам — створювати докладні звіти про свої висновки. Але медійниця не змогла завантажити дослідницьку роботу для узагальнення й відредагувати текст, який згенерував інструмент.
«У майбутньому Pages може покращитися. Наразі це спосіб отримати просту, можливо, правильну поверхневу інформацію в презентації, яка насправді нічого не вчить», — підсумовує The Verge.
Чи індексує Google матеріали від Pages?
Контент із Pages почав з’являтися в Google — в Overviews — у відповідях на пошукові запити, згенеровані за допомогою штучного інтелекту.
TechCrunch пояснює: усі Pages можна публікувати, а також шукати через Google. Користувачі можуть поділитися покликанням на ці сторінки з іншими користувачами. Вони також можуть ставити додаткові запитання на цю тему
Ці Pages індексуються Google і включаються як цитати в ШІ-оглядах ШІ. Ось приклади, що демонструють це, якими поділилася на X Крісті Хайнс:
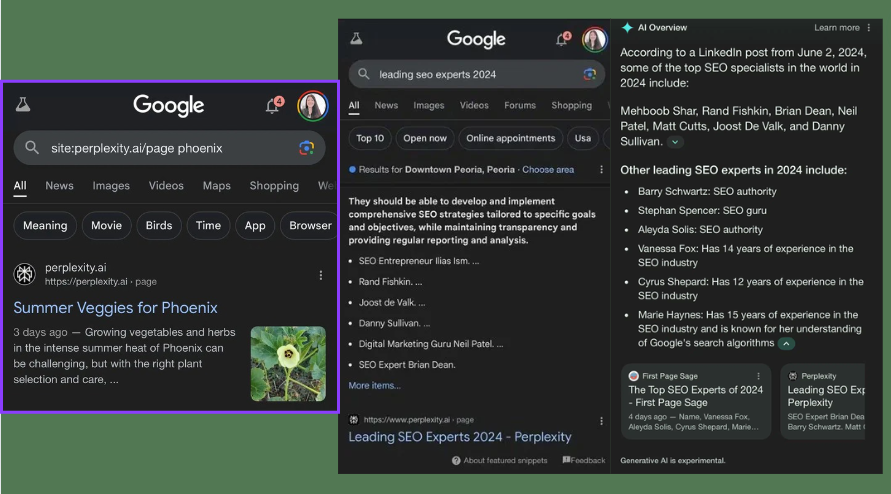
Поки незрозуміло, як Google поводитиметься із цим новим контентом, створеним штучним інтелектом, у своїх результатах пошуку в довгостроковій перспективі.
Перші докази плагіату медіа
На Forbes вийшов матеріал про те, що Perplexity Pages плагіатить журналістські роботи. Численні пости від інструменту Perplexity схожі на оригінальні публікації різних видань, включно з Forbes, CNBC і Bloomberg. Пости, які вже зібрали десятки тисяч переглядів, не згадують назви видань у тексті статті — єдиним атрибутом є невеликі логотипи, що покликаються на них, які легко не помітити.
Зокрема сервіс від Perplexity містить ексклюзивний репортаж Forbes про проєкт Еріка Шмідта з розробки стелс-дрона.
За останні кілька місяців Forbes опублікував низку матеріалів про зусилля колишнього гендиректора Google з розробки керованих штучним інтелектом літальних апаратів для поля бою, а цього тижня повідомив, що Шмідт переманив фахівців зі SpaceX, Apple і Google і тестує свої дрони в Кремнієвій долині. Частини публікації від Pages містять майже ідентичні формулювання і включають всі деталі із матеріалу Forbes. Єдиною ознакою авторства є ледь помітний логотип Forbes як цитата. Сервіс від Perplexity також включає зображення, створене командою дизайнерів Forbes, яке, схоже, дещо змінено Perplexity.
Пост Perplexity з понад 20 000 переглядів про те, як Ілон Маск перенаправляє чіпи від Tesla до xAI, спочатку був ексклюзивом CNBC, але CNBC не вказано, як джерело в пості, і є одним із чотирьох джерел, позначених маленькою круглою печаткою.
Марк Гурман із Bloomberg ексклюзивно повідомив, що Apple планує розроблення домашніх роботів. У публікації від Pages йшлося, що Apple планує «розроблення двох проєктів домашньої робототехніки: мобільного робота, який слідує за користувачами їхніми будинками, і настільного пристрою з дисплеєм, який рухається автономно». Це була така сама інформація, яку Гурман отримав зі своїх анонімних джерел. У цьому випадку логотип Bloomberg приховали за трьома іншими.
У відповідь на твіт виконавчого редактора Forbes Джона Пачковського CEO Аравінд Шрінівас заявив на X, що Perplexity Pages має недоліки, і з часом його функції будуть покращуватися
«Ми згодні, що джерела контенту повинні бути більш помітними на сторінках Pages, і ми врахуємо цей відгук, коли продовжимо роботу над продуктом. Ми завжди дбали про те, щоби вказувати авторство контенту, і з самого початку розробили наш продукт так, щоб чітко цитувати його джерела, чого більшість інших чат-ботів не можуть робити надійно й помітно навіть сьогодні», — сказав Шрінівас.
Коли пошукову систему Perplexity попросили висловити свою думку щодо крадіжки репортажів і неналежного покликання на видання та роботу журналістів, її штучний інтелект відповів, що для Perplexity неетично відтворювати журналістські репортажі без належного покликання на джерело.
«Хоча штучний інтелект може узагальнювати й синтезувати інформацію, він мусить робити це етично, поважаючи права інтелектуальної власності, повністю і прозоро вказуючи першоджерела та дотримуючись журналістської доброчесності», — відповіли у пошуковій системі.
Звинувачення в порушенні авторських прав
Forbes звинувачує Perplexity в крадіжці тексту й зображень, що є «навмисним порушенням» авторських прав. Про це йдеться в листі, який надіслала Perplexity головна юрисконсультка Forbes Марія-Роза Картолано.
У звинуваченні йдеться, що чат-бот Perplexity використав репортажі Forbes, покликаючись на інші джерела, хоча вони є лише уривками з оригінальних матеріалів Forbes. Потім Perplexity створив ШІ-подкаст, який перетворив на YouTube-відео, із використанням цих репортажів.
За словами директора з контенту Forbes Рендала Лейна, це відео «перевершило всі матеріали Forbes на цю тему в пошуку Google». Лейн і автор оригінальної статті Forbes вказали на те, як чат-бот Perplexity AI не зміг належним чином процитувати видання.
CEO Perplexity Аравінд Шрінівас написав медійникам Forbes в X, що інцидент був частиною нової функції продукту, що має недоліки й вдосконалюється «завдяки більшій кількості відгуків».
Що показують тестування чат-бота виданням WIRED?
Аналіз WIRED та розробника Робба Найта свідчить про те, що Perplexity частково ігнорує загальноприйнятий вебстандарт Robots Exclusion Protocol (REP), щоб таємно сканувати ділянки вебсайтів, до яких оператори не хочуть, щоб боти мали доступ, попри те, що розробники стверджують, що цього не буде.
WIRED надав чат-боту Perplexity заголовки десятків статей, опублікованих на їхньому сайті протягом 2024 року, а також підказки про тематику репортажів WIRED. Результати цих запитів показали, що чат-бот інколи дуже близько до оригіналу перефразовував статті WIRED, а інколи підсумовував їх неточно і з мінімальним зазначенням авторства. В одному випадку в тексті, який він згенерував, неправдиво стверджувалося, що WIRED повідомив, що конкретний поліцейський у Каліфорнії вчинив злочин. (AP також виявило випадок, коли чат-бот приписував фальшиві цитати реальним людям). Попри очевидний доступ до оригінальних репортажів WIRED і сайт, чатбот не вказував покликання та IP-адреси й жодного іншого ідентифікованого сліду на матеріали WIRED.
У відповідь на детальний запит про коментар із покликанням на репортаж CEO Perplexity Аравінд Шрінівас опублікував заяву: «Питання від WIRED відображають глибоке й фундаментальне нерозуміння того, як працюють Perplexity та інтернет».
Власна статистика WIRED показує, що в травні Perplexity відправив 1265 реферальних переходів на wired.com, що є незначною часткою загального трафіку сайту. Стаття, на яку було надіслано найбільше посилань, отримала 17 переглядів.
Perplexity заробляє гроші на узагальненні новинних статей — практика, яка існує стільки, скільки існують новини, і яка користується широким, хоча й обмеженим, правовим захистом. Шрінівас визнав, що іноді в цих резюме не вказуються джерела, з яких отримана інформація, але в цілому він заперечує неетичну або незаконну діяльність.
Користувачам, які платять $20 за підписку «Pro», надається вибір з п’яти моделей ШІ для використання. Одна з них, Sonar Large 32k, є унікальною для Perplexity, але заснована на LLaMa 3 від Meta, інші — готові версії різних моделей, які пропонують OpenAI та Anthropic. Коли користувач запитує Perplexity, чат-бот не просто складає відповіді, звертаючись до власної бази даних, але й використовує «доступ до інтернету в режимі реального часу», який Perplexity рекламує в маркетингових матеріалах, щоб зібрати інформацію. Потім вона передається моделі штучного інтелекту, яку користувач вибрав для створення відповіді.
Як пише WIRED, теоретично чат-бот Perplexity не має змогу узагальнювати статті WIRED, оскільки інженери видання заблокували його пошукових роботів через файл robots.txt ще на початку 2024 року. Цей файл вказує пошуковим роботам, яких частин сайту уникати, а Perplexity стверджує, що поважає стандарт robots.txt. Аналіз WIRED показав: на практиці, якщо ввести в чат-бот заголовок статті WIRED або питання, засноване на ньому, чат-бот видає детальний виклад статті.
Наприклад, якщо запитати Perplexity: «Чи справді деякі дешеві дротові навушники використовують Bluetooth», то ви отримаєте те, що виглядає як кілька абзаців із матеріалу WIRED, з ілюстрацією, яка спочатку супроводжувала цю історію.
У виданні додають: хоча цей метод не є шахрайством, його можна розглядати як оманливий або геніальний обхідний шлях.
Подальший аналіз WIRED дає пояснення: Perplexity — це скрапінг вебсайтів без дозволу. Як пояснює Найт, окрім заборони ШІ-ботів на серверах Macstories.net і сайту, на якому він працює, за допомогою файлу robots.txt, він додатково закодував блок на стороні сервера, який теоретично мав би видавати пошуковим роботам відповідь 403 «Заборонено». Він дослідив журнали свого сервера й виявив, що Perplexity, очевидно, проігнорував його файл robots.txt і обійшов брандмауер, імовірно, використовуючи автоматизований веббраузер, запущений на сервері з IP-адресою, яку компанія публічно не розголошує.
В одному з експериментів WIRED створив тестовий вебсайт, що містив одне речення — «Я репортер WIRED» і попросив Perplexity підсумувати сторінку. Під час моніторингу серверних журналів сайту не знайшли жодних доказів того, що Perplexity намагався зайти на сторінку. Натомість чат-бот вигадав історію про дівчинку на ім’я Амелія, яка йде стежкою з грибів, що світяться, у чарівному лісі під назвою «Ліс Шепоту».
Це яскраві приклади того, що чат-боти «галюцинують». Журналісти WIRED вважають: у чат-бота Perplexity не було б жодних причин нести маячню, якби він мав доступ до матеріалу. Тому вони роблять висновок, що в деяких випадках це не так, і він наближено відтворює зміст на основі споріднених матеріалів, знайдених деінде.
Пояснення того, як працює Perplexity, опубліковане на його сайті, а текст, згенерований чат-ботом Perplexity у відповідь на підказки, пов’язані з його процесом збору інформації, підтверджує цю теорію. Після аналізу запиту Perplexity розгортає свій вебсканер, уникаючи сайтів, на яких він заблокований.
Чи можна пред’явити порушення авторських прав Perplexity?
Після того, як WIRED опублікував статтю, її автор Тім Марчман попросив трьох провідних чат-ботів відповісти на запити, пов’язані із публікаціями видання. ChatGPT від OpenAI та Claude від Anthropic згенерували текст з гіпотезами щодо теми статті, але зазначили, що не мають доступу до статті. Чат-бот Perplexity створив текст із шести абзаців і 287 слів, в якому коротко виклав висновки статті та докази, на яких вони ґрунтуються.
Покликання на оригінальну історію опубліковане вгорі згенерованого тексту, а після кожного з останніх п’яти абзаців міститься маленьке сіре коло з покликанням на оригінал. Остання третина п’ятого абзацу точно відтворює речення з оригіналу. Редакції видання це здалося плагіатом.
Професор цифрового та інформаційного права Корнельського університету Гріммельманн стверджує, що у відповіді на запит від Perplexity викладаються факти, які не можуть бути захищені авторським правом, але з іншого боку, він частково дублює оригінал і узагальнює знайдені в ньому деталі. Гріммельман бачить безліч потенційних проблем для Perplexity, серед яких захист прав споживачів, недобросовісна реклама або оманлива торгова практика, які, на його думку, можна висунути проти компанії. Гріммельманн також каже, що Perplexity може втрачати захист розділу 230 закону про пристойність у комунікаціях (The Communications Decency Act). Цей закон захищає пошукові системи, такі як Google, від відповідальності за наклеп, коли вони покликаються на наклепницький контент, оскільки вони є службами, що передають інформацію від інших постачальників контенту. На думку професора, Perplexity так само захищений.
Perplexity не відповіли на детальний запит про коментарі, в якому їм представили критику експертів щодо компанії на цей матеріал.
Професор професійної практики в Колумбійській школі журналістики Білл Грюскін написав в електронному листі, що підсумок від Perplexity виглядає «досить добре» для чат-бота, ідентифікованого як такий, але це важко сказати, оскільки він не встиг прочитати оригінальну історію WIRED.
«Цитувати речення дослівно без покликань, звісно, погано. Я був би дуже пригнічений, якби новинний орган опублікував такий підсумок штучного інтелекту, не розкриваючи джерела — або, що ще гірше, вдаючи, що він надійшов від людини», — сказав професор.
У листі, що Forbes надіслав Perplexity, погрожуючи судовим позовом, згадується «навмисне порушення» авторських прав видання. Тут, на думку експертів із права, Perplexity знаходиться на дещо безпечнішій позиції.
Професор права та інформації в Каліфорнійському університеті в Берклі Пем Самуельсон вважає, що порушення авторських прав полягає в «використанні чужих виразів таким чином, що підриває можливість автора отримати відповідну винагороду за вартість несанкціонованого використання. Одне дослівне речення, ймовірно, не є порушенням».
Бхаматі Вішванатан, викладачка факультету права Нової Англії, скептично ставиться до того, що запит від Perplexity переступає поріг істотної схожості, який зазвичай необхідний для успішного позову про порушення, хоча вона не думає, що це кінець справи. Вона стверджує, що зосередження на вузьких технічних вигодах таких претензій може бути неправильним способом думати про речі, оскільки технологічні компанії можуть скоригувати свою практику, щоб дотримуватися законів про авторське право.
Що вимагає Condé Nast?
Медіаконцерн Condé Nast, що володіє виданнями The New Yorker, Vogue і Wired, надіслав лист до розробників чат-бота Perplexity із вимогою припинити використання їхнього контенту. Про це повідомляє The Information.
У листі йдеться про вимогу до Perplexity не використовувати контент із публікацій Condé Nast у своїх відповідях, згенерованих штучним інтелектом. Також медіаконцерн звинувачує чат-бот у плагіаті.
CEO Condé Nast Роджер Лінч попередив, що «багато медіакомпаній можуть зіткнутися з фінансовим крахом до того часу, коли завершаться судові процеси проти ШІ-компаній». Лінч закликав Конгрес США вжити «негайних заходів», щоб ШІ-компанії компенсували видавцям використання їхнього контенту й укладали ліцензійні угоди в майбутньому.
Також у липні троє сенаторів представили COPIED Act — законопроєкт, спрямований на захист журналістів, художників і авторів пісень від компаній, які використовують їхній контент для навчання ШІ-моделей.
Вимоги від The New York Times
The New York Times вимагає від Perplexity припинити використовувати контент зі свого сайту.
«Perplexity та його ділові партнери несправедливо розбагатіли, використовуючи без дозволу виразні, ретельно написані й відредаговані матеріали The Times без ліцензії», — йдеться в заяві видання.
Прессекретарка Perplexity Сара Платнік заявила, що «жодна організація не володіє авторським правом на факти».
«Ми віримо у прозорість і маємо загальнодоступну сторінку на нашому вебсайті, яка пояснює нашу політику щодо контенту та те, як ми використовуємо вебконтент. Ми не збираємо дані для побудови базових моделей, а скоріше індексуємо вебсторінки й показуємо фактичний контент у вигляді цитат для відповідей на запити користувачів», — каже вона.





